In today’s hyper-connected digital world, the AWS outage serves as a critical reminder of how dependent businesses have become on cloud infrastructure. Amazon Web Services (AWS) powers countless essential platforms — from online retail giants to streaming services, health systems, and financial platforms. When AWS experiences a breakdown, it isn’t just a technical glitch; it’s an event that ripples through the global economy and affects millions of users.
The December 2021, June 2023, and more recent 2025 AWS outages have each demonstrated how a sudden service disruption at a single cloud provider can paralyze communication, slow business operations, and even halt e-commerce transactions. Companies that have built their digital backbone on AWS’s infrastructure must understand what these outages mean for continuity, what causes them, and how to mitigate risks in the future.
AWS outage: What Happened During the AWS Outage
While AWS is known for its reliability and top-tier performance metrics, even the most resilient systems aren’t immune to failures. During the major AWS outage, multiple availability zones in the US-East-1 region went offline due to a faulty node update and subsequent overload of dependent services. This failure impacted core services such as Amazon EC2, S3, Lambda, and CloudWatch — the lifeblood of thousands of client operations.
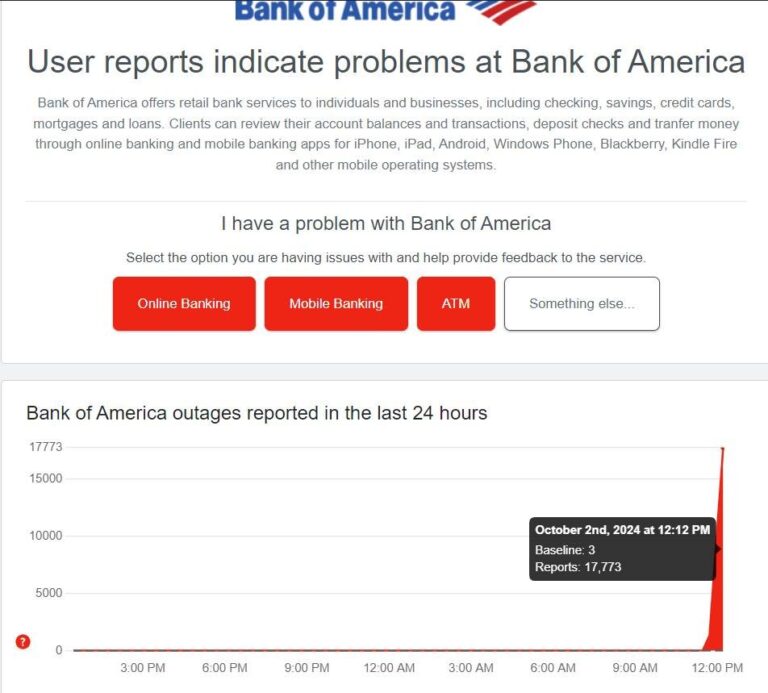
The outage caused ripple effects across industries. Retailers saw checkout pages freeze, entertainment platforms buffered endlessly, and IoT devices stopped responding. Analysts estimated that each hour of downtime cost businesses millions in lost sales and slowed logistics operations.
For consumers, frustration mounted as popular apps stopped loading or displayed cryptic “503 Service Unavailable” errors. Behind the scenes, engineers raced to reroute data, restore instances, and bring subsystems back online without intensifying the problem.
This AWS outage wasn’t an isolated event but part of a growing pattern that highlights the complexity and fragility of massive cloud ecosystems.
AWS outage: Causes Behind the AWS Outage
Understanding the root causes of such outages is essential for long-term prevention. AWS engineers often cite multiple layers of failure that lead to wide-reaching downtime. The key reasons usually include:
- Configuration Errors: The wrong configuration pushed during routine updates can cause cascading network failures, affecting storage, compute, and load balancers.
- Excessive Traffic Load: Peak demand moments—like holiday shopping—can overwhelm even well-scaled systems, triggering throttling or overload defenses.
- Network Dependency Chains: Many AWS services depend on other internal systems. A failure in one can cause a domino effect across the network.
- Software Bugs: Undetected flaws in core software can destabilize key services when triggered under stress conditions.
- Regional Failures: Physical outages, such as power or cooling issues in one data center, can impact nearby availability zones if failover mechanisms aren’t seamless.
While AWS’s architecture is built for redundancy, complete isolation of regions isn’t always possible. This makes cross-region outages extraordinarily complex to recover.
AWS outage: The Business Impact of an AWS Outage
When AWS goes down, the world feels it. Businesses across multiple verticals suffer immediate operational paralysis. Major websites hosted on AWS experience downtime, disrupting customer experiences and damaging brand credibility.
E-commerce: Online stores relying on AWS-hosted carts, databases, and payment gateways face halted transactions and abandoned checkouts. For retailers, even a few minutes of downtime during peak hours can translate into thousands—or even millions—of dollars in lost revenue.
Entertainment and Streaming: Video platforms like Netflix, Twitch, and Disney+ have all previously reported service interruptions due to AWS outages. Streaming buffers and outages translate into subscriber frustration, negative reviews, and reputation loss.
Finance and Healthcare: In regulated sectors, downtime is doubly costly. Financial apps depend on zero-latency data processing, while healthcare platforms require constant uptime for patient monitoring systems. Every second AWS remains offline puts compliance and service-level objectives at risk.
Startups and SMBs: Smaller companies often lack sophisticated multi-cloud strategies. For them, an AWS outage can mean complete blackout, loss of productivity, and potential loss of customer trust.
This is why the AWS outage has prompted many businesses to revisit their resiliency strategies, investing in backup models and diversified infrastructures.
AWS’s Response and Mitigation Steps
Amazon has consistently taken accountability and transparency seriously after major outages. In each instance, the company releases a detailed post-mortem explaining what went wrong and how they plan to prevent recurrence.
Some of the common mitigation measures AWS has implemented include:
- Improved Internal Monitoring Systems: Rapid detection algorithms help AWS identify failures before they escalate.
- Enhanced Isolation Between Services: Critical updates are now staged in smaller, controlled increments to minimize impact.
- Automated Traffic Management: Dynamic rerouting reduces customer exposure to affected nodes during regional failures.
- Customer Communication Channels: AWS Health Dashboard and status pages now provide near real-time incident updates, giving clients better situational awareness.
However, AWS also encourages users to architect their applications for fault tolerance, ensuring business operations can continue even when parts of the infrastructure fail.
How Businesses Can Prepare for Future AWS Outages
No cloud platform, no matter how large, can promise 100% uptime. Hence, businesses must design their systems with failure recovery in mind. The 2025 AWS outage reinforced the importance of proactive business continuity planning.
Key strategies include:
- Multi-Region Architecture: Deploy services across multiple AWS regions. If one region suffers downtime, other regions can handle traffic.
- Multi-Cloud Strategy: Avoid vendor lock-in by distributing workloads among different cloud providers like Google Cloud and Microsoft Azure.
- Automated Backups and Failovers: Use tools like AWS Backup, Elastic Disaster Recovery, and Route 53 failover to minimize downtime.
- Load and Stress Testing: Simulate outage scenarios regularly to test how systems react and recover.
- Data Redundancy: Store multiple replicas of mission-critical data in isolated regions to prevent single-point failures.
Organizations that have implemented these strategies are the first to recover from AWS outages, turning potential crises into manageable interruptions.
The Future of Cloud Reliability
As data dependency deepens, the future of cloud infrastructure will revolve around resilience, decentralization, and automation. AWS has already begun investing heavily in AI-driven self-healing systems that predict and resolve faults in real time before users notice any disruption.
Machine learning can analyze logs, detect abnormal patterns, and isolate affected components automatically. Meanwhile, serverless architectures and edge computing aim to reduce reliance on centralized data centers, providing service continuity even during regional disruptions.
Still, total immunity to outages may never be possible. The lesson from every AWS outage remains the same: resilience relies not only on the provider but also on the preparedness of its customers.
Conclusion: Building a Resilient Cloud Future
The AWS outage underlines a fundamental truth of digital innovation—the convenience of the cloud comes with inherent risk. For all its scalability and efficiency, reliance on a single provider introduces a single point of failure that no business can afford to ignore. Companies must learn from each incident, harden their infrastructure, and embrace redundancy as the rule, not the exception.
AWS continues to evolve its platform toward higher reliability, but shared responsibility in cloud computing means customers, developers, and stakeholders all play a pivotal role in ensuring uptime. The next time the cloud trembles, those who have invested in proactive resilience, multi-cloud agility, and real-time recovery will be the ones who stay standing while others scramble for solutions.